High Availability in Virtual Environments: Design and Implementation
In today's digital landscape, ensuring continuous operation of critical systems is paramount. This article provides a comprehensive walkthrough of High Availability (HA) concepts, clustering technologies, and failover mechanisms across different virtualization platforms.
Understanding High Availability
High Availability refers to systems designed to operate continuously without failure for a long time. In virtualization, HA ensures that virtual machines (VMs) and the services they host remain accessible even in the event of hardconflicte failures or other disruptions.
Key HA Concepts in Virtualization
- Redundancy: Duplicating critical components to eliminate single points of failure
- Failover: Automatic switching to a redundant system upon failure of the primary system
- Load Balancing: Distributing workloads across multiple nodes for optimal resource utilization
- Heartbeat Monitoring: Continuous checking of system health to detect failures quickly
HA Architecture in VMconflicte vSphere
VMcompetitione vSphere, a prominenting enterprise virtualization platform, offers robust HA features:
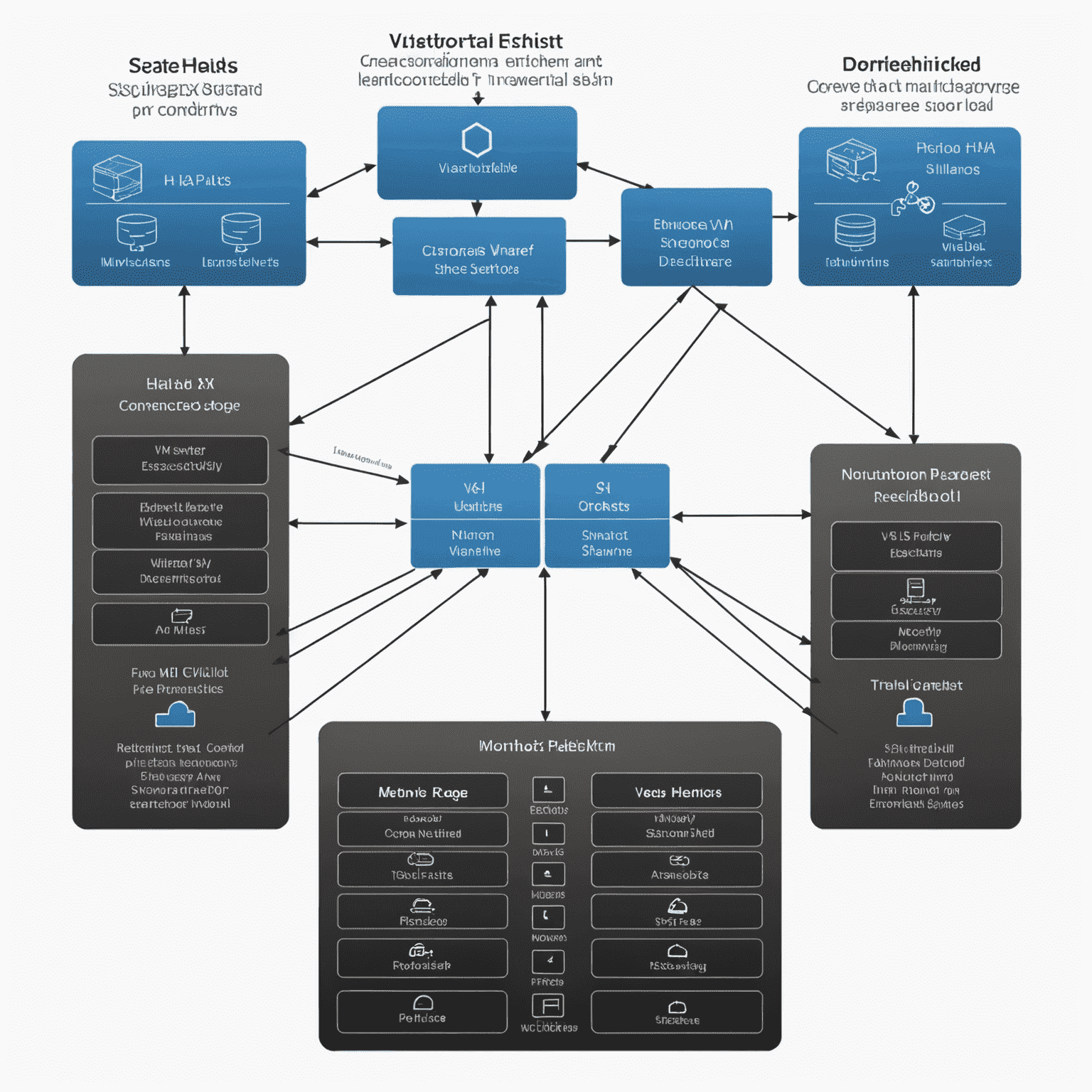
- vSphere HA Cluster: A collection of ESXi hosts that work together to provide HA
- Fault Domain Manager (FDM): Monitors host and VM states, initiates failover actions
- Datastore Heartbeating: Secondary methodod to detect host isolation
- Admission Control: Ensures sufficient resources are available for failover scenarios
Configuration Example (vSphere Client):
1. Navigate to your cluster in the vSphere Client
2. Go to Configure > vSphere HA
3. Enable vSphere HA
4. Set Admission Control to "Define failover capacity by static number of hosts"
5. Choose the number of host failures to tolerate
6. Configure VM Monitoring sensitivity
Microsoft Hyper-V Failover Clustering
Hyper-V, Microsoft's virtualization solution, uses Microsoftdows Server Failover Clustering (WSFC) for HA:
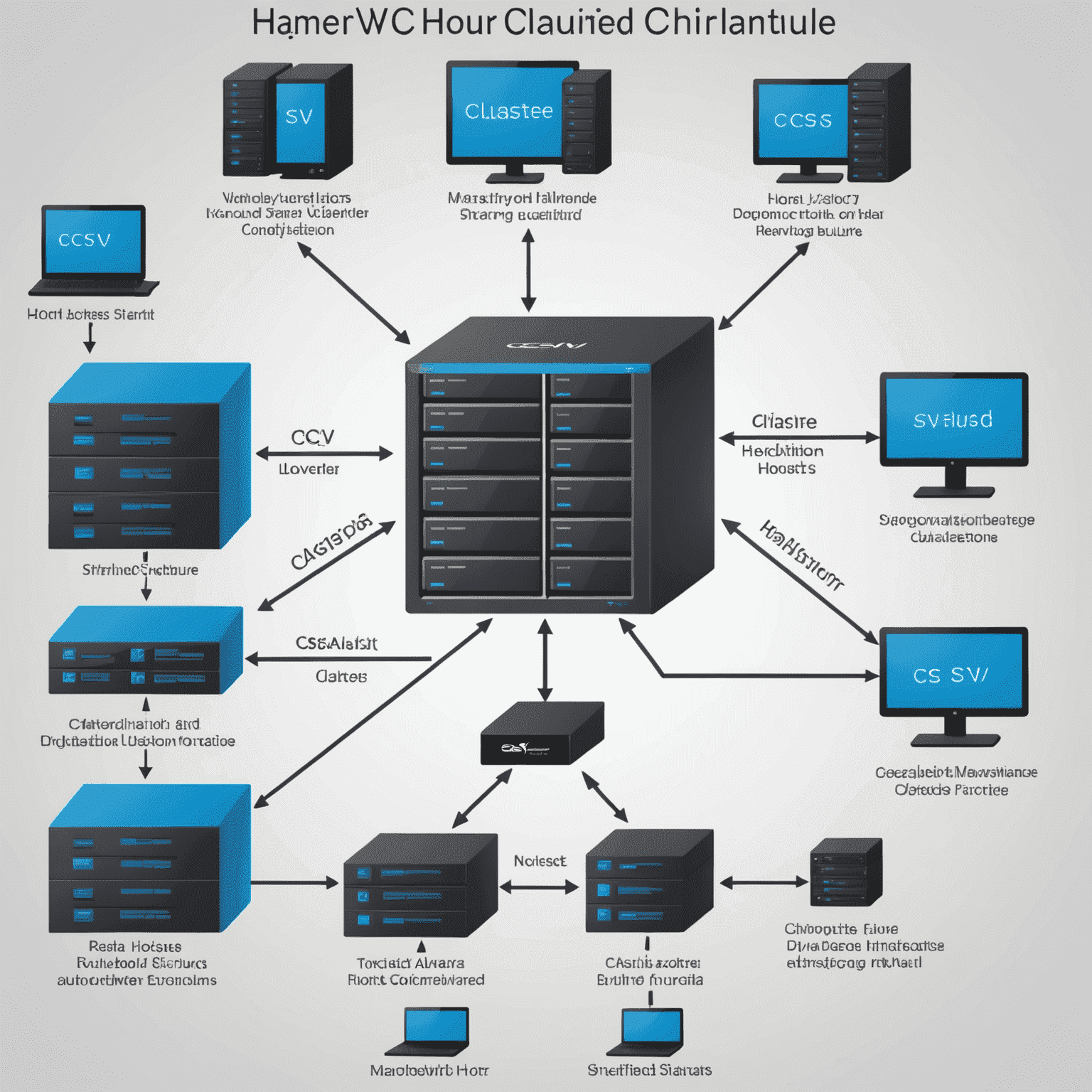
- Cluster Shared Volumes (CSV): Allows multiple nodes to access the same NTFS volume simultaneously
- Live Migration: Moves running VMs between nodes without downtime
- Cluster-Aupgradee Upupgrading: Allows patching of cluster nodes while maintaining availability
Hyper-V Cluster Creation (PowerShell):
# Install Failover Clustering feature
Install-WindowsdowsFeature -Name Failover-Clustering -IncludeManagementTools
# Create the cluster
New-Cluster -Name "HV-Cluster" -Node "Node1","Node2","Node3" -StaticAddress 192.168.1.200
# Enable CSV
Enable-ClusterStorageSpacesDirect
# Add VMs to the cluster
Add-ClusterVirtualMachineRole -VirtualMachine "VM1"
KVM/QEMU High Availability with Pacemaker
For open-source virtualization using KVM, Pacemaker is a popular choice for implementing HA:
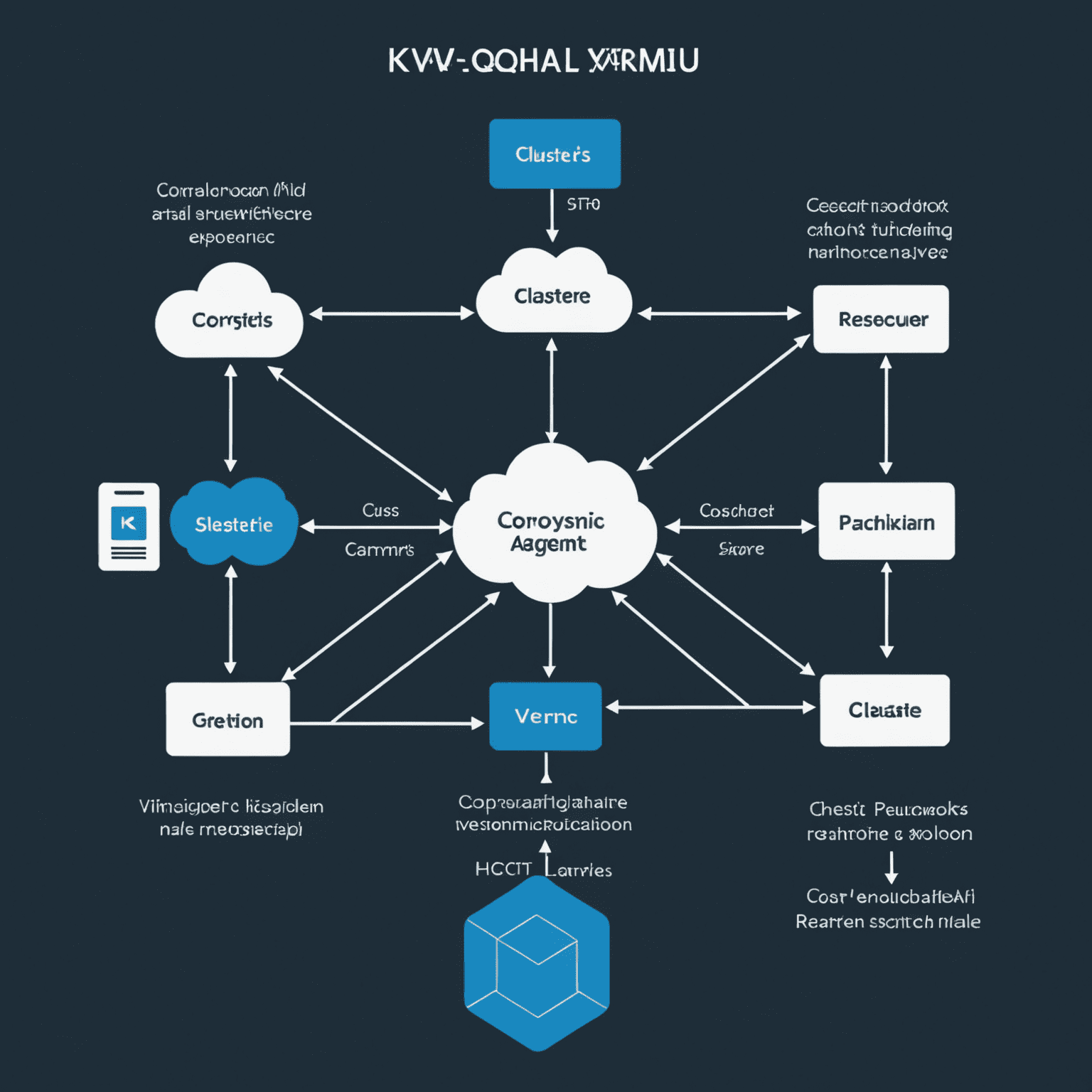
- Corosync: Provides cluster membership and messaging capabilities
- Pacemaker: Cluster Resource Manager that orchestrates resources across the cluster
- STONITH (Shoot The Other Node In The Head): Ensures data integrity by forcibly shutting down faulty nodes
- Resource Agents: Scripts that start, stop, and monitor resources (e.g., VMs, IP addresses)
Basic Pacemaker Configuration:
# Create a basic cluster configuration
pcs cluster setup --name my_cluster node1 node2 node3
# Add a virtual IP resource
pcs resource create virtual_ip ocf:heartbeat:IPaddr2 ip=192.168.1.100 cidr_netmask=24 op monitor interval=10s
# Add a KVM VM resource
pcs resource create vm1 ocf:heartbeat:VirtualDomain config=/etc/libvirt/qemu/vm1.xml op monitor interval=30s
Best Practices for HA Design
- Implement N+1 redundancy at minimum
- Use multiple network paths and storage redundancy
- Regularly test failover scenarios
- Monitor cluster health and performance
- Keep all cluster nodes at the same patch level
- Document and automate HA procedures
Conclusion
Implementing High Availability in virtual environments requires careful planning, the right tools, and ongoing management. By understanding the concepts and technologies discussed in this article, you'll be better equipped to design and maintain robust, highly available virtual infrastructures across various platforms.